
在人工智能领域,像GPT-4和qwen等大型语言模型(LLMs)已经成为研究和开发的焦点。然而,这些模型通常需要大量的计算资源和网络连接才能运行。幸运的是,随着Ollama工具的出现,个人用户和开发者能够轻松在本地环境中运行和利用这些强大的模型。
Ollama简介
Ollama是一款本地大语言模型工具,使用户能够快速运行Llama 2、Code Llama和其他模型。用户可以自定义和创建他们自己的模型。
使用Ollama
先说一下我的电脑情况,垃圾配置,19年的华为Matebook14,参数如下:
i7 8565U/8GB/512GB/MX250
三系统:Windows10+Linux Mint+FydeoOS
由于配置比较垃圾,我估计最多能跑7B的模型。 事实证明也是如此:本机器可以流畅跑Gemma 2B,Qwen 4B,Qwen 1.8B,较卡顿跑出Qwen 7B,Gemma 7B,Code Llama 7B。实测在Linux mint上跑的效果好过Windows,遗憾Linux mint没有分配足够空间,内存爆满,所以最后又转到了Windows。下面就是安装过程。
Linux安装
用以下命令直接安装:
curl -fsSL https://ollama.com/install.sh | sh
Windows安装
以下文章有详细的安装和使用教程:
https://www.sysgeek.cn/ollama-on-windows/
常用命令
拉取模型:
ollama pull llama2
运行模型:
ollama run llama2
删除模型:
ollama rm llama2
列出所有模型:
ollama list llama2
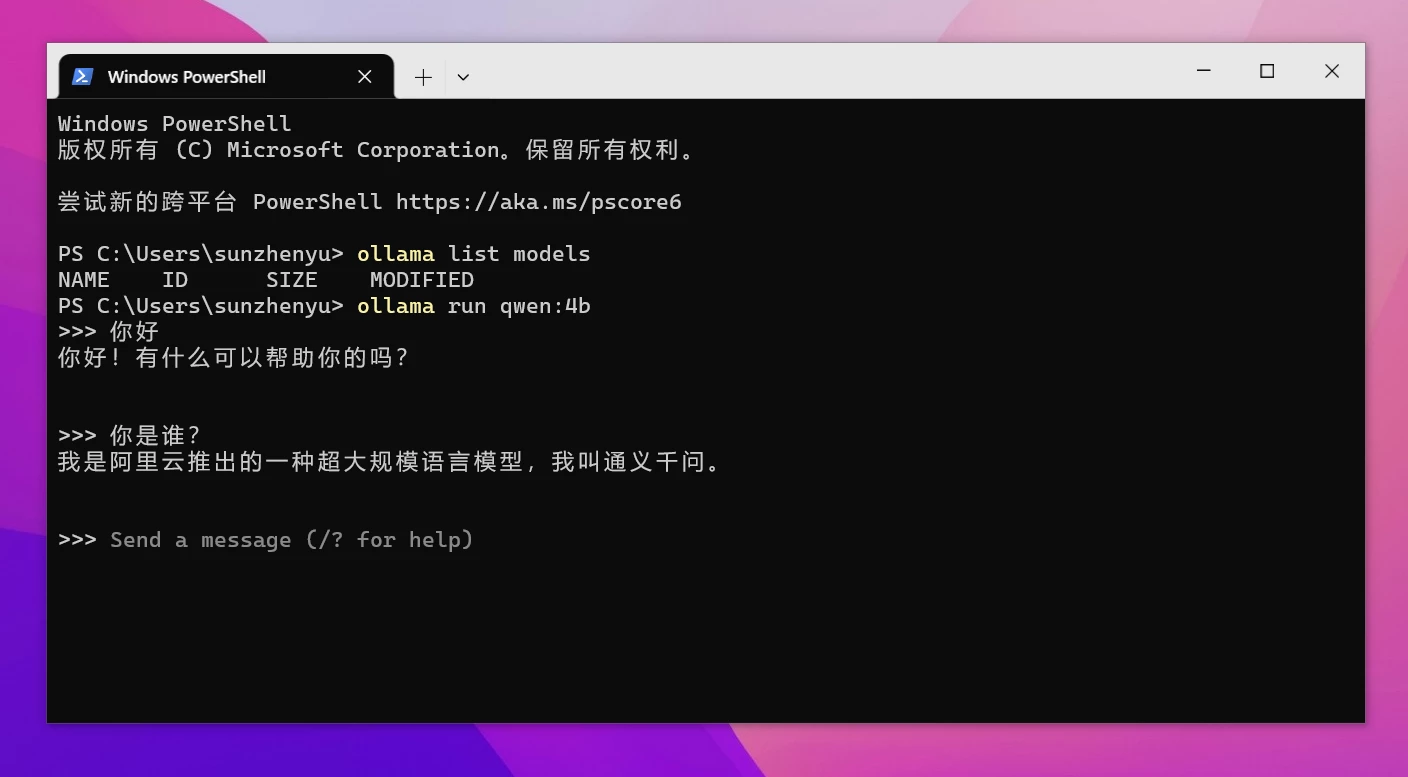
使用WebUI调用本地大模型
使用OpenWebUI
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 WebUI,适用于各种 LLM 运行程序,支持的 LLM 运行程序包括 Ollama 和 OpenAI 兼容的 API。
官方文档:https://docs.openwebui.com/
需要安装Docker,不推荐。
使用LobeChat
前面讲过,最近更新支持本地模型调用了,缺点是还需要Docker部署。
使用ChatBox
这应该是最简单最容易上手的,只要安装即可。
Chatbox官网 - 办公学习的AI好助手,官方免费下载 (chatboxai.app)
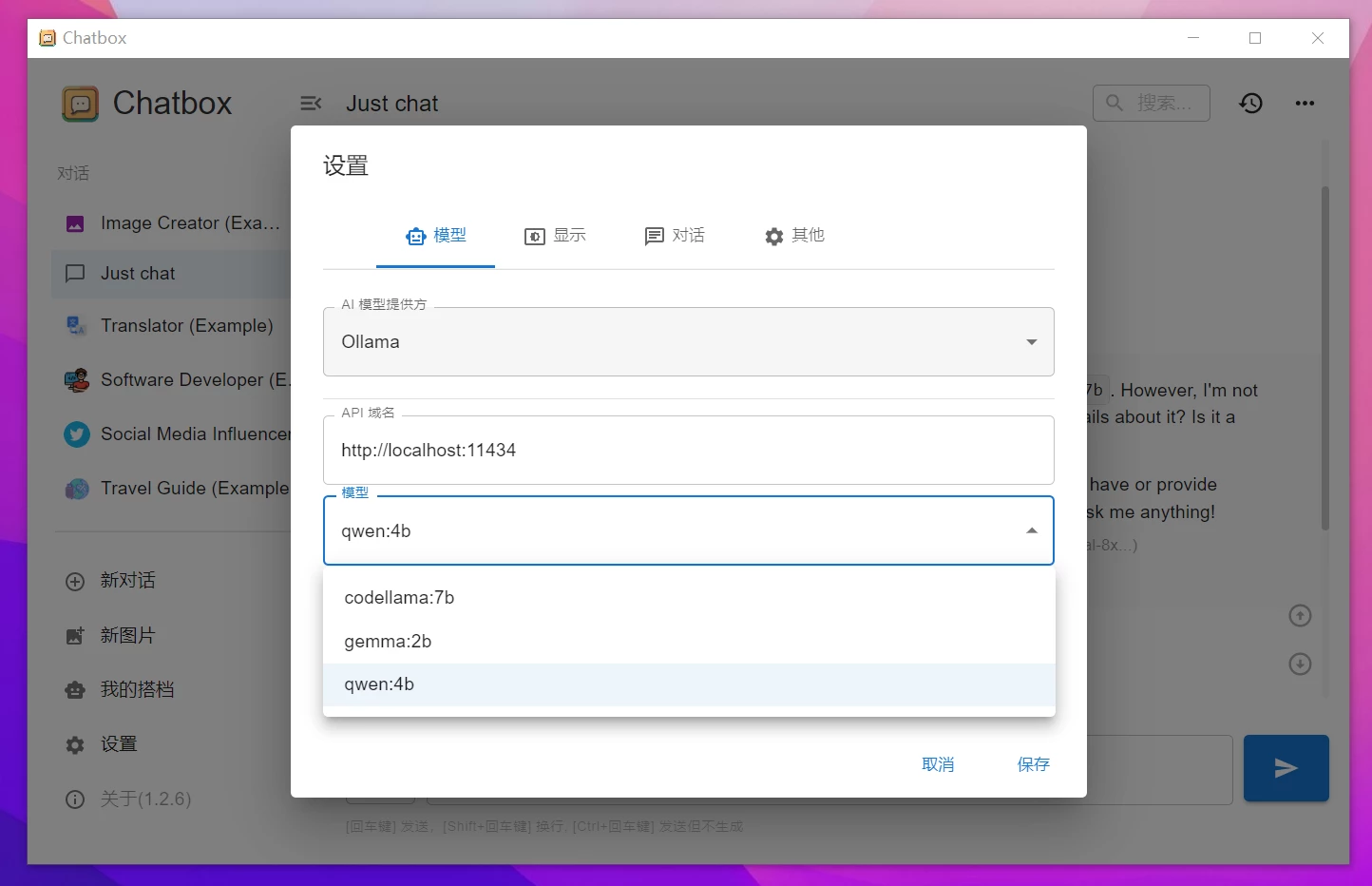
使用也很简单,启动ollama,然后打开ChatBox按如图配置即可(会自动检测,几乎不用手填写):
吐槽
等我有钱了一定要买一台好电脑!!!!